Hệ thống xử lý dữ liệu luồng và kiến trúc
Bài viết “Streaming Systems and Architectures” – Tác giả: Jayant Shekhar và Amandeep Khurana được xuất bản trong tạp chí ;login Spring 2016, Vol. 41, No. 1.
Hệ thống quản lý dữ liệu (Data Management Systems)
Hệ thống quản lý dữ liệu đã tồn tại hàng thập kỷ nay và tạo thành một nền công nghiệp mạnh mẽ mà chúng ta đều biết đến. Các nhà cung cấp đáng chú ý trong thị trường này là những công ty tên tuổi như Oracle, Microsoft, Teradata, IBM; đây là những công ty có giá trị nhất thế giới trong lĩnh vực phát triển hệ thống quản lý dữ liệu. Dữ liệu là thành phần cốt lõi của rất nhiều vấn đề liên quan đến mô hình kinh doanh của tổ chức, doanh nghiệp; họ có thể phải tốn đến hàng triệu đô la Mỹ để xây dựng một hệ thống dữ liệu có thể thu thập (ingest), lưu trữ (store), phân tích (analyze), và sử dụng những dữ liệu liên quan để phục vụ ngược lại cho các khách hàng của doanh nghiệp, các kênh kinh doanh, và các thị trường kinh doanh khác nhau. Mặc dù đã có sự trưởng thành so với thời gian ban đầu, ngành công nghiệp quản lý dữ liệu lại đang trải qua một sự gián đoạn tại thời điểm hiện tại. Nguyên nhân là do sự bùng nổ nhanh chóng của dữ liệu được tạo ra bởi con người và máy móc ngày càng rẻ hơn, khả năng kết nối ngày càng nhiều hơn. Do vậy, nó đã tạo nên nhu cầu xử lý dữ liệu lớn trong các hệ thống quản lý dữ liệu nhằm phục vụ nhu cầu xử lý dễ dàng, linh động và giá thành ngày càng thấp hơn.
Hệ thống quản lý dữ liệu có thể chia thành nhiều phân nhóm khác nhau và phụ thuộc vào tiêu chí mà người dùng lựa chọn. Hệ cơ sở dữ liệu (databases), hệ thống tập tin (file systems), hệ thống hàng đợi (message queues), các công cụ đánh giá kinh doanh (bussiness intelligence tools) là những phần trong một hệ sinh thái nhằm phục vụ những mục đích khác nhau trong một kiến trúc lớn hơn của hệ thống quản lý dữ liệu; và những điều này sẽ giúp bạn xử lý những vấn đề trong chiến lược kinh doanh. Một cách khác để phân loại các hệ thống này là dựa vào cách xử lý dữ liệu: dữ liệu tĩnh (at rest) hoặc dữ liệu động (in motion).
Dữ liệu tĩnh (Data at Rest)
Dữ liệu tĩnh: dữ liệu được lưu trữ trên thiết bị số, analog.
Những hệ thống phục vụ cho việc quản lý dữ liệu tĩnh bao gồm hệ cơ sở dữ liệu, hệ thống tập tin, cơ chế xử lý (processing engines), và hệ thống điện toán lưới (grid commputing systems). Hầu hết các hệ thống xử lý dữ liệu đã được lưu trữ tồn tại nhiều tầng lưu trữ dữ liệu (storage tier) khác nhau, trong khi tầng xử lý dữ liệu (compute tier) thực hiện xử lý hoặc làm sạch các nguồn dữ liệu đầu vào, kết quả xử lý sẽ được lưu trữ vào một hệ thống lưu trữ khác phục vụ phân tích kết quả.
Dữ liệu động (Data in Motion)
Dữ liệu động: dữ liệu đang xử lý, đang truyền tải trên kênh truyền.
Những hệ thống phục vụ cho việc quản lý dữ liệu động như hàng đợi tin nhắn (message queues) hoặc hệ thống xử lý dữ liệu luồng (stream processing systems). Kiến trúc hệ thống xử lý dữ liệu động bao gồm các thành phần được kết nối và làm việc chung với nhau theo một chuỗi xử lý; hướng tới một trạng thái cuối cùng mà người dùng mong muốn. Một số hệ thống đơn giản thu thập các dữ liệu từ nguồn phát sinh dữ liệu như log, sự kiện dữ liệu,… Một số khác thực hiện xử lý theo luồng dữ liệu liên tục và ghi dữ liệu vào hệ thống lưu trữ (data at rest). Các hệ thống xử lý luồng có thể khác nhau về tính chất xử lý hoặc mô hình thiết kế hệ thống.
Hệ thống xử lý luồng (Streaming Systems)
Có hai dạng hệ thống xử lý luồng dữ liệu: hệ thống xử lý luồng đầu vào (stream ingestion systems) và hệ thống phân tích luồng dữ liệu (stream analytics systems).
Stream ingestion system: thực hiện thu thập các luồng dữ liệu đầu vào; xử lý trực tuyến các dữ liệu từ nguồn phát sinh (access log, event log,…) và xuất ra hệ thống phân tích dữ liệu để tiến hành trích xuất các dữ liệu cần thiết.
Stream analytics system: là hệ thống xử lý dữ liệu được thu nhận từ hệ thống thu thập đầu vào. Việc xử lý dữ liệu này được thực hiện trên các gói tin đi vào hệ thống mà không cần xử lý trên tập tin hoặc không cần lưu vào cơ sở dữ liệu trước khi phân tích.
Hệ thống xử lý luồng đầu vào cung cấp nguồn dữ liệu cho hệ thống phân tích; kết quả đầu ra của hệ thống phân tích có thể chuyển ngược lại cho hệ thống phân tích đầu vào để tiếp tục xử lý hoặc được ghi vào hệ thống dữ liệu tĩnh (data at rest) để thực hiện lưu trữ. Tôi sẽ tiếp tục phân tích các hệ thống này trong phần tiếp theo, bao gồm nội dung:
- Kafka: hệ thống hàng đợi dữ liệu (message queue) phục vụ chức năng thu thập dữ liệu đầu vào (stream ingestion system)
- Spark: hệ thống xử lý thực hiện phân tích dựa trên các mẩu dữ liệu nhỏ trên luồng dữ liệu.
- Storm: thực hiện xử lý dựa trên từng sự kiện riêng lẻ trên luồng dữ liệu.
- Flink: mộ thệ thống xử lý luồng phân tán được xây dựng trên cơ chế xử lý hàng loạt dữ liệu (batch processing).
Apache Kafka
Apache Kafka là một hệ thống xử lý hàng đợi theo cơ chế publish-subscribe; Kafka còn hỗ trợ triển khai hệ thống thu thập log theo mô hình phân tán (distribute), phân chia (partition), và đồng bộ (replicate). Mã nguồn Kafka được thiết kế cho việc xử lý dữ liệu lớn khi đọc/ghi dữ liệu, giảm độ trễ trong quá trình truyền tải dữ liệu.
Kafka thường được triển khai theo mô hình cluster; mỗi node trong cluster được gọi là broker. Mỗi broker có thể quản lý hàng trăm megabyte đọc/ghi dữ liệu một giây từ hàng nghìn người dùng một lúc. Một cluster có thể mở rộng một cách linh động mà không gây ra tình trạng dừng hệ thống.
Kafka cung cấp một khái niệm gọi là topic, mỗi dữ liệu đến hệ thống sẽ thuộc một topic cụ thể. Hệ thống gởi dữ liệu đến Kafka được gọi là producer. Hệ thống tiếp nhận đầu ra từ Kafka được gọi là consumer.
Việc truyền tải dữ liệu giữa các hệ thống khác với Kafka broker được thực hiện thông qua giao thức TCP; việc phát triển, phân tích dữ liệu có thể thực hiện trên nhiều nền tảng ngôn ngữ lập trình khác nhau.

Hình 1: Kafka producers, cluster, partitions, and consumer groups
Các topic được phân chia thành những phân vùng dữ liệu khác nhau. Mỗi phân vùng dữ liệu được sếp thứ tự trong quá trình truy cập dữ liệu. Mỗi gói dữ liệu gởi đến hệ thống sẽ được đánh số thứ tự theo ID. Như hình 1, ta có bốn phân vùng dữ liệu trong một topic. Các phân vùng có thể dịch chuyển trên các máy chủ khác nhau, và các topic có thể mở rộng một cách dễ dàng. Mỗi phân vùng dữ liệu có thể được đồng bộ sang một broker khác để tăng tính sẵn sàng của dữ liệu.
Các hệ thống produccer có thể thực hiện ghi dữ liệu vào các phân vùng dữ liệu theo cơ chế round-robin. Trong trường hợp có nhiều producer, mỗi producer có thể chọn ngẫu nhiên một phân vùng để tiến hành ghi dữ liệu, việc này sẽ làm giảm số lượng kết nối đến mỗi broker.
Việc phân vùng dữ liệu cho phép những consumer đọc dữ liệu từ những phần khác nhau của một topic; hệ thống comsumer có thể đọc dữ liệu theo cơ chế round-robin giữa các broker khác nhau để phục vụ mục đích cân bằng tải cho hệ thống. Kafka thực hiện lưu trữ các dữ liệu vào ố cứng và sao chép một bản tương tự để tăng khả năng chịu lỗi của hệ thống. Apache Kafka bao gồm Java client và Scala client trong việc liên kết với Kafka cluster.
Có nhiều hệ thống khác có thể tích hợp vào Kafka bao gồm Spark Streaming, Storm, Flume và Samza.
Spark Streaming
Spark Streaming đóng vai trò thượng tầng trong toàn bộ nền tảng Spark computing framework. Spark là một hệ thống xử lý dữ liệu hàng loạt (batch processing) có thể hoạt động đơn lẻ hoặc đóng vai trò là quản lý dữ liệu tương tự như YARN hoặc MEsos. Spark Streaming hỗ trợ các kỹ thuật xử lý dữ liệu như windowing, joining stream,…

Hình 2: DStreams consists of multiple RDDs based on the time interval
Spark Streaming có thể nhận dữ liệu từ nhiều nguồn khác nhau, bao gồm Kafka, Flume, Kinesis, Twitter, và TCP sockets. Một số ngữ cảnh chính khi triển khai hệ thống Spark Streaming mà bạn cần biết là Discretized Streams (DStreams); có thể được hiểu là một luồng dữ liệu liên tục được tạo ra từ các nguồn đầu vào
Bên trong một DStream bao gồm các Resilient Distributed Datasets (RDDs) đóng vai trò cốt lõi trong kiến trúc Spark.
Các RDD được tạo ra dựa trên các khoảng thời gian (time interval) được cấu hình trong ứng dụng Spark Streaming; nó đóng vai trò định mức tần số dữ liệu sẽ được xử lý bởi ứng dụng. Hình 2 mô tả kiến trúc hoạt động của mô hình DStreams.
Spark streaming xử lý dữ liệu với các tính năng cấp cao như map, reduce, join, và window. Sau khi xử lý , các dữ liệu sẽ được lưu trữ vào các hệ thống như HDFS, HBase, Solr, và kết nối đến các hệ thống hiển thị trên giao diện quả lý hoặc được điều khiển đến một hệ thống Kafka khác cho việc xử lý tiếp theo.
Khi nhận được các luồng dữ liệu đầu vào, Spark Streaming phân chia dữ liệu thành các khối nhỏ hơn (mini batch). Mỗi khối này được lưu trữ trong một RDD và các RDD này sau đó sẽ được xử lý bởi Spark để tạo ra các RDD mới.

Hình 3: Diagram of Spark Streaming showing Input Data Sources, Spark DStreams, and Output Stores
Đối với yêu cầu “xử lý dữ kiện phức tạp” – Complex Event Processing (CEP), Spark Streaming hỗ trợ
stream-stream join; bao gồm inner-joins, left, right, và full outer-joins.
Storm
Apache Storm [3] là một dự án mã nguồn mở được thiết kế theo kiến trúc phân tán trong việc xử lý dữ liệu luồng. Một hệ thống Storm bao gồm hai thành phần chính là: master node được gọi là Nimbus và worker node được gọi là Supervisor. Nimbus chịu trách nhiệm phân phối các mã dữ liệu trong toàn bộ cluster, phân tác vụ đến các máy chủ và giám sát các tác vụ thất bại. Supervisor thực hiện tiếp nhận các tác vụ mà nó được phân công từ Nimbus; Storm hoạt động dựa trên nền tảng Zookeeper với mục đích quản lý/ phối hợp giữa các node và quản lý trạng thái lưu trữ của dữ liệu.
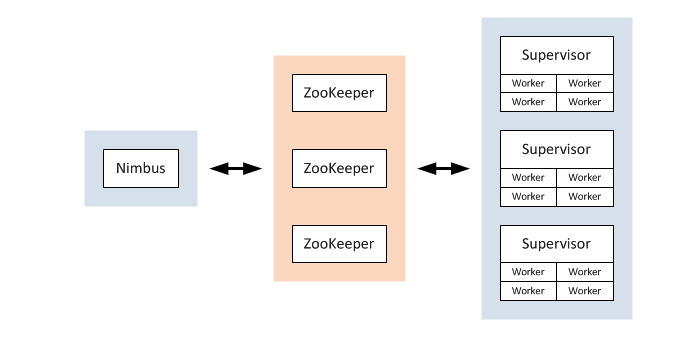
Hình 4: Storm Cluster
Ứng dụng xử lý luồng trong Storm được định nghĩa bởi các mô hình hệ thống. Các mô hình này thật chất là các cấu trúc luận lý phục vụ cho việc tính toán của ứng dụng. Các node trong mô hình sẽ quyết định phương thức (method) xử lý dữ liệu, và các node liên kết với nhau sẽ quyết định luồng (flow) xử lý dữ liệu.
Thành phần cốt lõi của một hệ thống Storm được gọi là Stream. Cấu trúc của Stream bao gồm các tập hợp dữ liệu (tuples of data). Mỗi phần tử trong một tập hợp có thể là bất kỳ loại dữ liệu nào. Kết quả xử lý dữ liệu từ hệ thống Storm có thể xuất ra thành một hoặc nhiều luồng dữ liệu khác nhau; hoặc có thể chuyển đến hệ thống Kafka hay một hệ thống lưu trữ/ cơ sở dữ liệu. Storm cung cấp hai khái niệm cơ bản trong quá trình xử lý dữ liệu được gọi là Bolt và Spout. Bạn có thể triển khai bolt và spout để tạo ra một ứng dụng xử lý luồng dữ liệu theo mong muốn.

Hình 5: Tuples of data
Một spout có thể được xem là một nơi tiếp nhận các dữ liệu đầu vào trong mô hình kiến trúc Storm. Nó đóng vai trò thu thập các dữ liệu từ hệ thống Kafka hoặc từ Twitter API hoặc bất kỳ hệ thống nào cung cấp cơ chế xử lý dữ kiện theo luồng.
Một bolt có thể tiếp nhận dữ liệu từ một hoặc nhiều nguồn dữ liệu mà spout chuyển đến; nó làm việc hoàn toàn dựa trên kiến trúc mà bạn đã quy hoạch ban đầu. Dữ liệu đầu ra của một bolt có thể phục vụ cho một bolt khác để tiếp tục xử lý. Bolt có thể làm được mọi thứ từ việc chay các hàm xử lý, thu thập các trường dữ liệu trong một tập hợp, phân tích các luồng dữ liệu, thực hiện xử lý streaming-join, tương tác với cơ sở dữ liệu và nhiều tính năng khác. Một hệ thống mạng lưới các thành phần bolt/spout tạo thành một mô hình hệ thống Storm như hình 6.
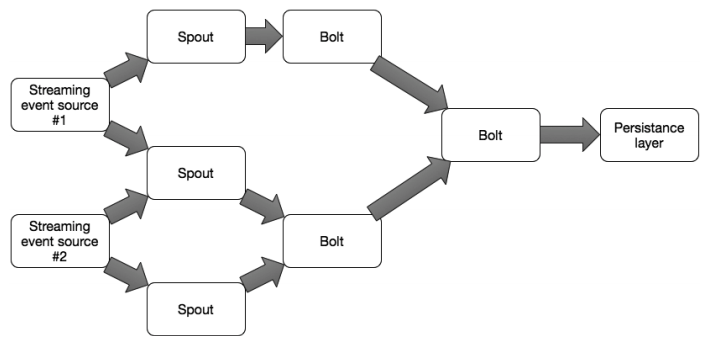
Hình 6: A Storm topology consisting of bolts and spouts
Một hệ thống như vậy sẽ hoạt động cho đến khi bạn kết thúc nó. Mỗi node trong hệ thống bạn có thể thiết lập xử lý song song và Storm sẽ tiến hành phân bổ tài nguyên theo yêu cầu dựa trên việc tạo thêm các thread xử lý. Khi có một tác vụ thất bại, Storm sẽ tự động khởi khộng lại chúng.
Storm cung cấp ba cơ chế đảm bảo an toàn cho dữ liệu:
- At-most-once processing: đây là chế độ đơn giản nhất và thích hợp trong trường hợp một tập dữ liệu yêu cầu xử lý không quá một lần. Việc mất mát dữ liệu trong quá trình xử lý có thể được chấp nhận trong tình huống này. Nếu quá trình xử lý thất bại tại chế độc này, Storm sẽ tiến hành loại bỏ dữ liệu và không xử lý gì cả.
- At-least-once processing: chế độ này yêu cầu các tập dữ liệu (typle) phải được xử lý ít nhất một lần. Tuy nhiên, việc xử lý dữ liệu nhiều hơn một lần sẽ được áp dụng. Trong tình huống này, hệ thống của bạn sẽ phải chấp nhận có sự sai sót dữ liệu (không đáng kể) trong kết quả xử lý.
- Exactly-once processing: đây là một chế độ phức tạp và tốn kém hơn các chế độ còn lại. Thông thường, một hệ thống bên ngoài như Trident sẽ được sử dụng để đảm bảo tính chính xác của dữ liệu.
Storm cung cấp cho người dùng những kỹ thuật cấu hình hệ thống khác nhau để đạt được mục đích xử lý của hệ thống. Twitter gần đây đã thông báo đến cộng đồng một dự án mới là Heron; nó được phát triển dựa trên những kinh nghiệm từ hệ thống Storm và Heron hứa hẹn là một giải pháp thay thế Storm trong tương lai.
Apache Flink
Apache Flink, tương tự Spark, là một hệ thống xử lý phân tán và xử lý dữ liệu khối (batch processing). Thành phần cốt lõi của Flink cung cấp tính năng phân phối dữ liệu, kết nối và tăng khả năng chịu lỗi cho các máy chủ trong hệ thống cluster.
Hệ thống xử lý chính của kiến trúc Flink cần được nói đến chính là DataStreams. Các nguồn dữ liệu mà Flink có thể tiếp nhận đến từ một hệ thống Kafka, Twitter, và ZeroMQ. Nguồn dữ liệu sau khi xử lý được ghi vào tập tin dữ liệu hoặc ghi thông qua giao thức socket. Việc hoạt động của Flink tiến hành qua cơ chế JVM trên máy cục bộ hoặc xử lý theo kiến trúc cluster. Quá trình chuyển đổi dữ liệu được Flink hỗ trợ trên DataStreams bao gồm: Map, FlatMap, Filter, Reduce, Fold, Aggregations, Window, WindowAll, Window Reduce, Window Fold, Window Join, Window CoGroup, Split, và một số dạng khác.
Ứng dụng DataStream xử lý liên tục và trong thời gian dài, Flink cung cấp cơ chế giảm thiểu khả năng lỗi hệ thống thông qua cơ chế Lightweight Distributed Snapshot; dựa theo phương thức hoạt động của Chandy-Lamport distributed snapshot. Flink vẫn có thể vẫn tiếp tục các quá trình tính toán dữ liệu trong khi tiến hành các bảo trì hệ thống. Flink thực hiện kiểm tra trạng thái dữ liệu để bảo đảm nó có thể phục hồi khi xuất hiện hư hỏng trong dữ liệu.
DataStream API hỗ trợ chức năng chuyển đổi (transformation) trên các luồng dữ liệu thông qua cơ chế cửa sổ (window). Người dùng có thể tùy biến kích thước window, tần suất tiếp nhận dữ liệu hoặc các phương thức gọi dữ liệu. Window có thể hoạt động dựa trên nhiều chính sách điều khiển như count, time, và delta.
Apache Flink có những đối tượng tương tự Apache Spark, nhưng khác nhau cơ bản về kiến trúc thiết kế. Flink thể hiện tính ưu việt trên chính kiến trúc và khả năng xử lý của nó; bao gồm batch, micro-batch, và xử lý sự kiện riêng lẻ, tất cả chỉ trong một hệ thống duy nhất.
Một số kiến trúc hệ thống
Kiến trúc streaming thông thường sẽ bao gồm nhiều hệ thống tích hợp với nhau để xử lý các mẫu dữ liệu theo ý muốn thiết kế. Việc tùy biến các kiến trúc sẽ được qua những giai đoạn:
- Xác định các điểm tiếp nhận dữ liệu
- Xác định các điểm xuất dữ liệu xử lý
Có hai kiểu xác định điểm tiếp nhập dữ liệu trong mô hình phổ dụng là: tích hợp hệ thống hàng đợi (Kafka) như là nguồn sinh dữ liệu, và tích hợp hệ thống hàng đợi như là một hệ thống xử lý dữ liệu (Storm, Spark Sreaming, hoặc Flink)

Hình 7: Streaming architecture consisting of Kafka, Storm, Spark Streaming, and Flink
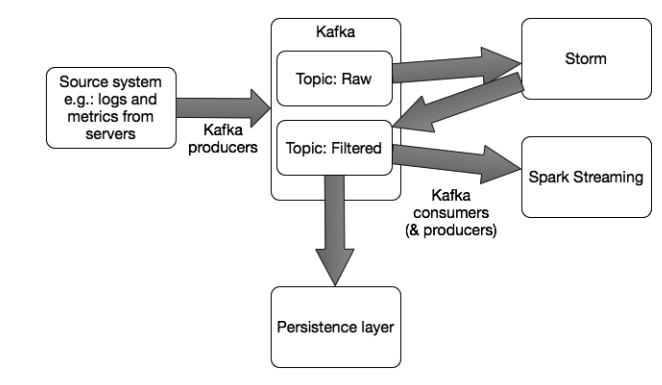
Hình 8: Streaming access pattern showing Storm processing events first, with results then processed by Spark Streaming and also persisted
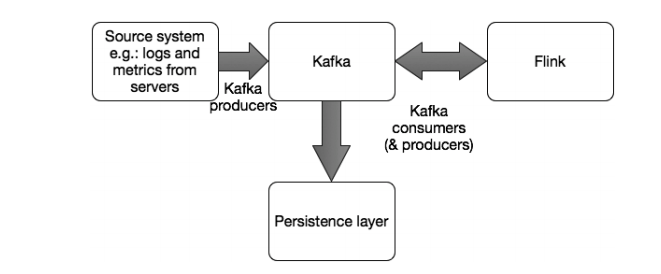
Hình 9: Streaming access pattern showing Flink doing the job of both Storm and Spark Streaming in the use case
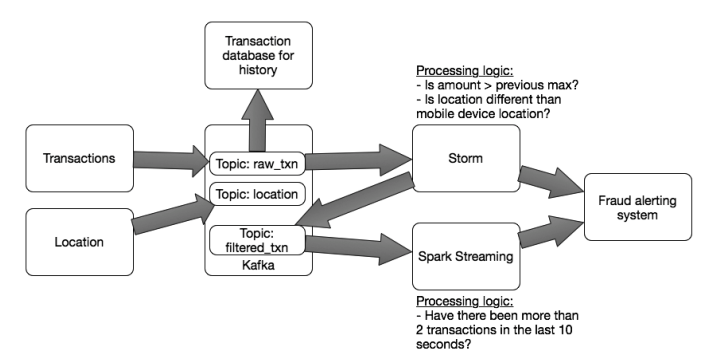
Hình 10: Streaming architecture for detecting fraudulent transactions
Kết luận
Ngày càng nhiều tổ chức, doanh nghiệp thực hiện kết hợp các luồng dữ liệu liên tục vào kiến trúc CNTT của họ. Chúng ta đã thảo luận các vấn đề xử lý các dữ liệu đầu vào thông qua Kafka, Spark, Storm và Flink phục vụ cho phân tích dữ liệu. Người dùng cần nắm các tính chất của từng hệ thống để áp dụng linh động trong việc phát triển và mở rộng hệ thống một cách thành công. Tôi hi vọng bài viết này sẽ cung cấp đầy đủ các thông tin nhằm giúp bạn có thể lựa chọn, thiết kế và bắt đầu triển khai một hệ thống streaming của bạn.
Tham khảo
- Apache Kafka — http://kafka.apache.org/.
- Apache Spark Streaming — http://spark.apache.org/streaming/.
- Apache Storm — http://storm.apache.org/.
- Apache Flink — https://flink.apache.org/.
- Apache Spark — https://spark.apache.org/.
- Trident — http://storm.apache.org/documentation/Trident-tutorial.html.
- Apache Hadoop YARN — https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html.
- Apache Mesos — http://mesos.apache.org/.
- Spark RDDs — http://spark.apache.org/docs/latest/programming-guide.html#resilient-distributed-datasets-rdds.
- Heron stream processing system by Twitter — https://blog.twitter.com/2015/flying-faster-with-twitter-heron.
Khi cần hỗ trợ xin liên hệ với chúng tôi:
Công ty phần mềm Nhân Hòa
Trụ sở Hà Nội: Tầng 4 – Toà nhà 97 – 99 Láng Hạ, Đống Đa, Hà Nội
Chi nhánh HCM: 270 Cao Thắng (nối dài), Phường 12, Quận 10, TP HCM
Chi nhánh Vinh – Nghệ An: Tầng 2 Tòa nhà Sài Gòn Sky, ngõ 26 Nguyễn Thái Học, phường Đội Cung, TP. Vinh, Nghệ An
Hotline: 19006680

